
Desarrollo web
Simplificando nuestros entornos de desarrollo con Docker Compose
¿Por qué Docker? Uno de los pilares que fundamentan el día a día del equipo de desarrollo en acceseo es el uso de Docker, en

¿Por qué Docker? Uno de los pilares que fundamentan el día a día del equipo de desarrollo en acceseo es el uso de Docker, en

Como muchos de vosotros sabréis, VS Code es un editor de código fuente que nos permite trabajar con nuestro código gracias a la infinidad de

Introducción El mundo del desarrollo ha vivido una gran evolución en su corta historia. En sus inicios, se instalaban los servicios habituales para llevar a

Con la introducción gradual del tipado en PHP se ha abierto un abanico de posibilidades que está cobrando cada día más fuerza entre la comunidad

En otros artículos hemos hablado de los motivos por los que utilizar Symfony como nuestra herramienta de desarrollo, buenas prácticas o cómo crear nuestro primer
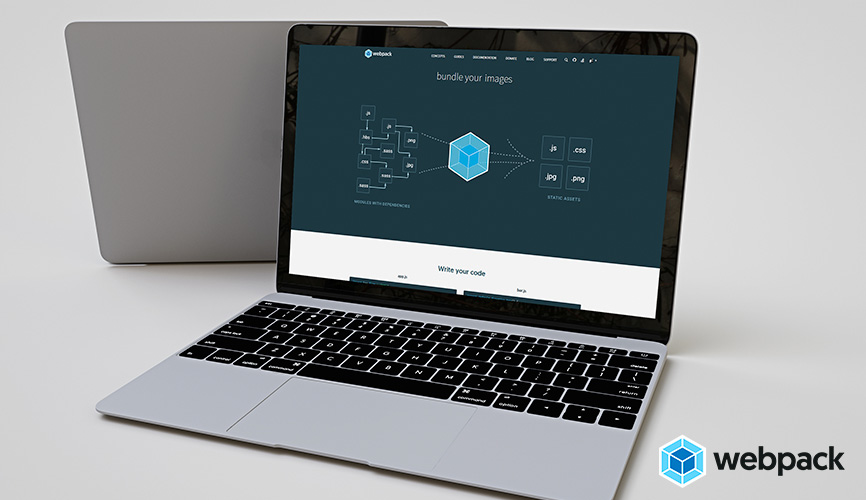
Los empaquetadores, comúnmente llamados en términos anglosajones, bundlers, son ya una herramienta imprescindible en cualquier entorno web moderno que se precie. Con la reciente ganancia

Symfony es un framework PHP que recientemente ha cumplido los 500 Millones de descargas y es conocido por su gran ecosistema de componentes. También es la

Composer se ha convertido en una herramienta fundamental del ecosistema PHP. Se trata de un gestor de dependencias que nos facilita la siempre tediosa tarea
Cuéntanos qué ocurre
y nos pondremos con ello lo antes posible.